


For anyone who has spent an afternoon tweaking text prompts only to watch the AI reinterpret “cinematic lighting” as a fluorescent office glow, the appeal of a reference-first approach is immediate. The industry has spent years chasing better prompt engineering, but a quieter shift is happening—one that prioritizes what you can show over what you can describe. Seedance 3.0 sits at the center of this shift, offering a workspace where images, video clips, and audio files carry as much weight as the words you type. It is not another text-to-video generator dressed up with a new interface. It is a different way of working, one that treats references not as optional extras but as the foundation of the creative process.
Why Reference-Driven Generation Changes the Creative Calculus
The traditional text-to-video workflow is built on a fundamental mismatch: you are asking a model to translate abstract language into concrete visuals. The model has no way to know what you mean by “that specific shade of blue” or “the way the light falls on her face.” It guesses. Sometimes it guesses well. Often it does not. The reference-driven approach sidesteps this problem by giving the model something to look at before it generates a single frame. You are not asking it to imagine; you are asking it to extend, adapt, or remix what you have already provided.
The Practical Difference in Daily Use
From a practical user perspective, this changes the rhythm of creation. Instead of generating, reviewing, rewriting the prompt, and generating again, you spend more time curating references and less time fighting the model’s interpretation. The output is not guaranteed to be perfect on the first try—complex scenes with multiple interacting elements may still require multiple passes—but the direction is clearer, and the iterations are more productive. You are troubleshooting specific details rather than hoping the model understands the brief.
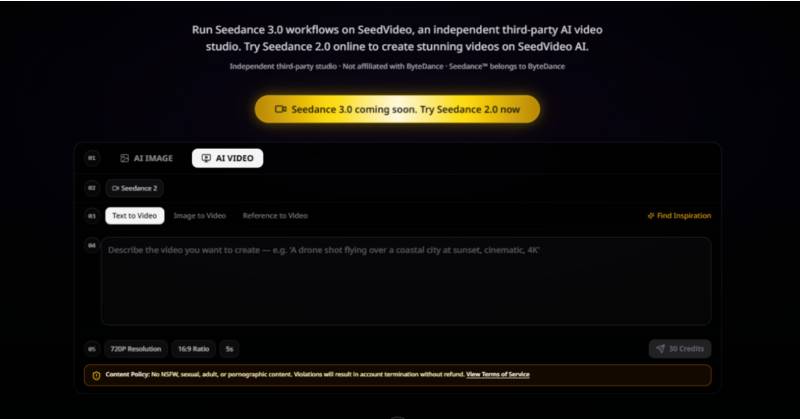
Inside the Workspace: How the Platform Actually Works
The platform organizes its workflow around the idea that creation is rarely a linear process. You move between uploading, describing, generating, and refining, with each step feeding back into the next. The workspace is designed to keep you in the flow rather than forcing you to switch between different tools or tabs.
Step 1: Upload Your Creative Anchors
What You Can Bring Into the Workspace
The upload step accepts images, video clips, and audio files. These are not just placeholders; they are active references that the model uses to inform the generation. A character still becomes the visual anchor for facial consistency across shots. A location photo sets the scene’s visual tone. A video clip demonstrates camera movement or action pacing. An audio track provides rhythmic and emotional cues that sync with the visual output. The system accepts multiple inputs simultaneously, so you can build a layered creative brief that combines visual and audio references.
Why This Matters for Consistency
The most persistent problem in AI video generation is inconsistency—faces that change between shots, scenes that lose their visual identity, clothing that shifts colors. By anchoring the generation to specific references, the platform addresses this problem at the source. The model has a fixed point of reference to return to, which reduces the drift that plagues text-only generation. In my testing, the consistency improvement was most noticeable in projects that required recognizable characters or branded visual elements.
Step 2: Describe and Tag Your Vision
The Tagging System That Bridges Words and References
Once your references are uploaded, you describe what you want to create using natural language. The key difference is the tagging system: you can reference your uploaded materials directly in your prompt using the @ symbol. This tells the model exactly which reference to apply to which part of your description. Instead of writing “a character who looks like the person in the reference image,” you simply tag the image. The model understands the connection and preserves the visual identity across the generated frames. This is where the platform moves from being a generator to being a collaborator—you are directing, not guessing.
Step 3: Generate, Extend, and Edit
Beyond the First Output
The generation is not the end of the process. The platform supports video extension, allowing you to lengthen existing clips, merge segments, or edit specific portions without regenerating the entire piece. This is particularly valuable for narrative work where continuity matters. You can also apply style transfers from a library of over 100 artistic styles, giving you additional creative flexibility without leaving the workspace. The editing capabilities mean you are not locked into the first output—you can refine, adjust, and iterate until the video matches your vision.
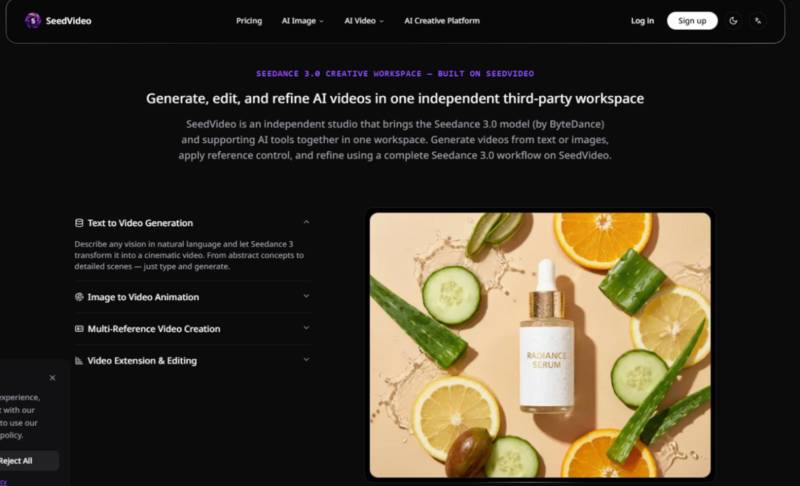
A Closer Look at the Tool Ecosystem
SeedVideo is not a single model; it is a workspace that aggregates multiple AI capabilities. The platform centers on Seedance 2.0 and Seedance 3.0 for video generation, but it also includes GPT Image 2 for image synthesis and Suno AI Music for audio composition. Beyond these, the platform supports additional models including Kling 3, Grok, Veo 3, and dozens of others, with Veo 4 listed as coming soon.
The All-in-One Advantage
The practical benefit is workflow continuity. You can generate a concept image using GPT Image 2, feed it directly into the video pipeline as a reference, compose an original music track with Suno AI Music, and sync it all to the final video output—all without switching tabs or managing multiple subscriptions. For creators who are tired of juggling different tools for different parts of the process, this consolidation is a genuine time-saver. The platform is an independent third-party studio, which means it is not affiliated with Google, OpenAI, ByteDance, or any other AI model provider. This independence offers flexibility but also means you are relying on a third party for access to models that may have their own update cycles.
Where This Workflow Excels and Where It Falls Short
The reference-first approach is not a universal solution. It works best in scenarios where visual consistency matters—character-driven narratives, branded content, serialized video projects. The platform’s strength is in maintaining faces, clothing, text, scenes, and visual styles across multiple generations. Where it faces limitations is in highly complex scenes with multiple interacting elements or unusual physical dynamics. The quality of the output depends heavily on the quality of the references; blurry or poorly composed input will not produce crisp, professional footage. The platform also enforces a strict content policy that prohibits NSFW, sexual, adult, or pornographic content.
A Quick Comparison: Reference-First vs. Text-Only Workflows
| Aspect | Reference-First Workflow | Text-Only Workflow |
| Creative Control | Direct visual and audio references anchor the output | Relies entirely on text interpretation |
| Consistency | Maintains faces, clothing, scenes across shots | Often loses continuity between generations |
| Iteration Efficiency | Fewer generations needed due to precise guidance | Multiple attempts required to approximate intent |
| Learning Curve | Requires understanding of reference tagging | Simple prompt entry, but harder to control |
| Output Predictability | Higher, given clear references | Lower, due to model interpretation variance |
Real-World Applications: Who Benefits Most
Content Creators and Serialized Production
For creators who need to produce consistent video content at scale, the reference system reduces the overhead of re-prompting. You can establish a visual identity once and reuse it across multiple clips without worrying about the AI forgetting what your character looks like.
Brand and Marketing Teams
Promotional videos benefit from the ability to reference existing brand assets—logos, product shots, color palettes—and apply them consistently across generations. The audio sync feature also makes it easier to match video to existing campaign music or jingles.
Independent Filmmakers and Digital Artists
For smaller teams that lack the budget for traditional animation or live-action production, Seedance 3.0 AI Video Generator offers a way to produce cinematic-quality footage with reference-controlled consistency. The editing and extension features support longer-form projects that would be impractical with single-shot generators.
Honest Limitations: What the Platform Does Not Promise
No tool is perfect, and this one is no exception. The quality of the output is directly tied to the quality of the input—blurry or poorly composed references will not become crisp, professional footage. Complex scenes with multiple characters or intricate physical interactions may require multiple generations to get right. The platform is also an independent third-party studio, which means it is not affiliated with any AI model provider. While this independence offers flexibility, it also means you are relying on a third party for access to models that may have their own update cycles and availability. The platform’s content policy is strict, and violations can result in account termination.
The Takeaway for Your Creative Workflow
The reference-first approach is not about replacing traditional video production or promising magic from bad ideas. It is about changing the relationship between creator and tool—moving from guessing to directing, from describing to showing. For creators who are tired of wrestling with text prompts that never quite capture what they mean, this workflow is worth exploring. It fits best in environments where visual consistency matters, where audio-visual sync is part of the brief, and where the creator is willing to invest time in curating good reference material. It is not the only AI video tool on the market, but it is one of the few that treats you like a director rather than a spectator.












.